
In April 2018, TSB Bank attempted to migrate 1.3 billion customer records from a legacy processing platform to a new system built by its Spanish parent company. The migration did not account for undocumented interdependencies between data structures. Within hours, 1.9 million customers were locked out of their accounts. Some saw other customers' balances. Fraud cases spiked. The outage lasted weeks.
The total cost: £330 million in remediation, compensation, and lost revenue (The Independent). CEO Paul Pester resigned under pressure (BBC News). The UK's Treasury Select Committee launched a parliamentary inquiry. The Financial Conduct Authority levied £48.65 million in fines (Reuters). Eighty thousand customers left the bank.
TSB's board did not fully grasp the risk until it became a headline. That is the scenario this guide helps you prevent. Your board does not need to understand how legacy transaction infrastructure works. They need to understand what happens when it fails, what it costs to do nothing, and what a structured investment looks like. This article gives you the language, the data, and a ready-to-use presentation template to make that case.
What the Board Actually Cares About
Boards do not think in programming languages. They think in three categories: liability, resilience, and agility. Every argument you make needs to land in one of those buckets.
Liability and Regulatory Exposure
Regulatory bodies increasingly treat system failures as governance failures. TSB's £48.65 million fine came not because of a software bug but because the FCA found that the bank "failed to plan for the IT migration properly" and lacked "adequate risk management systems" (BBC News). Under frameworks like DORA in the EU and the FCA's operational resilience rules in the UK, boards carry personal accountability for technology risk. A system that runs on code no one can maintain is not a technology problem. It is a fiduciary liability.
Modern board risk reporting standards reinforce this shift. According to VComply's 2025 analysis of board expectations, directors now expect risk reports that are "clear, forward-looking, and directly tied to business impact." If your legacy systems do not appear in your enterprise risk register with quantified financial exposure, you have a governance gap.
Operational Resilience and Revenue Risk
Core processing systems handle the transactions that generate revenue. When they fail, revenue stops. A CTO risk assessment guide documents that a 100-millisecond increase in e-commerce platform latency can reduce conversion rates by 7%. For systems processing thousands of transactions per hour, even minor degradation carries a measurable cost. A full outage is catastrophic.
The maintenance burden compounds the problem. Organizations running legacy transaction infrastructure spend as much as 80% of their IT budget on keeping existing systems running, leaving minimal capacity for new capabilities (CTO Legacy Risk Guide). That is not a technology complaint. That is a capital allocation problem the board can see on a balance sheet.
Competitive Agility
Every feature your engineering team cannot build because they are maintaining 40-year-old transaction processing code is a feature your competitor ships first. According to the CTO Legacy Risk Guide, 62% of organizations continue to operate outdated software despite known risks. The top reason for delay? "It still works" (cited by 50% of organizations). That phrase is the most expensive sentence in enterprise IT. The system works until it does not, and the cost of failure grows every quarter the organization delays.
The Data You Need Before You Walk In
A board presentation without hard numbers is a conversation. A board presentation with hard numbers is a decision. Before you request a meeting, gather these six data points:
| Metric | Why the Board Cares |
|---|---|
| System age (years in production) | Establishes the scale of the liability. Federal systems flagged by the GAO range from 23 to 59 years old. |
| Last major change date | Reveals how long the system has been in maintenance-only mode. No changes = no one willing to touch it. |
| Staff who can maintain it | 71% of mainframe teams are already understaffed. If your number is single digits, the board needs to know. |
| Retirement timeline of those staff | The GAO found that some experts who maintained critical federal systems are "retired or deceased." Map your own timeline. |
| Cost per incident (last 3 years) | Converts abstract risk into a dollar figure the CFO can validate. |
| Estimated downtime cost per hour | Anchors the risk matrix. If the system processes $1.2M per hour, a 4-hour outage is $4.8M. |
If you cannot gather all six, start with what you have. Incomplete data presented honestly is more credible than polished estimates. The goal is to move the conversation from "we think this is risky" to "here is what it costs us."
What Not to Say (and What to Say Instead)
The language you use determines whether the board hears a technology request or a business risk. Every term in the left column triggers the board's "this is an IT problem" filter. The right column reframes each concept in language that connects to liability, revenue, and competitive position.
| Instead of Saying… | Say This |
|---|---|
| "COBOL" | "Core transaction processing systems (some 40 to 60 years old)" |
| "Technical debt" | "Deferred operational liability" |
| "Unit test coverage" | "Validated failure detection" |
| "Shared state" | "Undocumented interdependencies" |
| "Modernization" | "Operational resilience investment" |
| "Refactoring" | "Reducing single points of failure" |
| "Legacy migration" | "Controlled transition to supported infrastructure" |
| "Code freeze" | "System that cannot safely accept changes" |
| "End of life" | "Operating beyond vendor support with no safety net" |
| "Sprint velocity" | "Product delivery speed" |
Practice this vocabulary before the meeting. A single slip into jargon gives the board permission to categorize your request as "IT wants more money" rather than "the business has an unhedged liability."
The Risk Matrix Slide
If your presentation has one slide that drives a decision, this is it. The risk matrix plots each core system on two axes: probability of failure (low to high) and business impact if failure occurs (low to catastrophic). The result is a four-quadrant grid.
How to score probability of failure. Assign each system a score based on: age of the codebase, number of people who can maintain it, frequency of recent incidents, and whether it has known security vulnerabilities. The GAO found that 7 of 11 critical federal systems have known security vulnerabilities (FedGov Today). If your systems share these characteristics, probability is not theoretical.
How to score business impact. Use the revenue-per-hour figure for each system. Layer on regulatory fine exposure, breach notification costs, and reputational damage estimates. A system that processes payroll for 50,000 employees has a different impact profile than a reporting dashboard.
What lands in the top-right quadrant. Systems with high probability of failure and catastrophic business impact require immediate action. These are the systems the board needs to fund first. Everything else can be sequenced in later phases. This quadrant is your ask.
Present this slide in color. Red for the top-right quadrant (immediate action), amber for adjacent quadrants (planned action), green for low-probability/low-impact systems (monitor). Board members process visual risk intuitively.
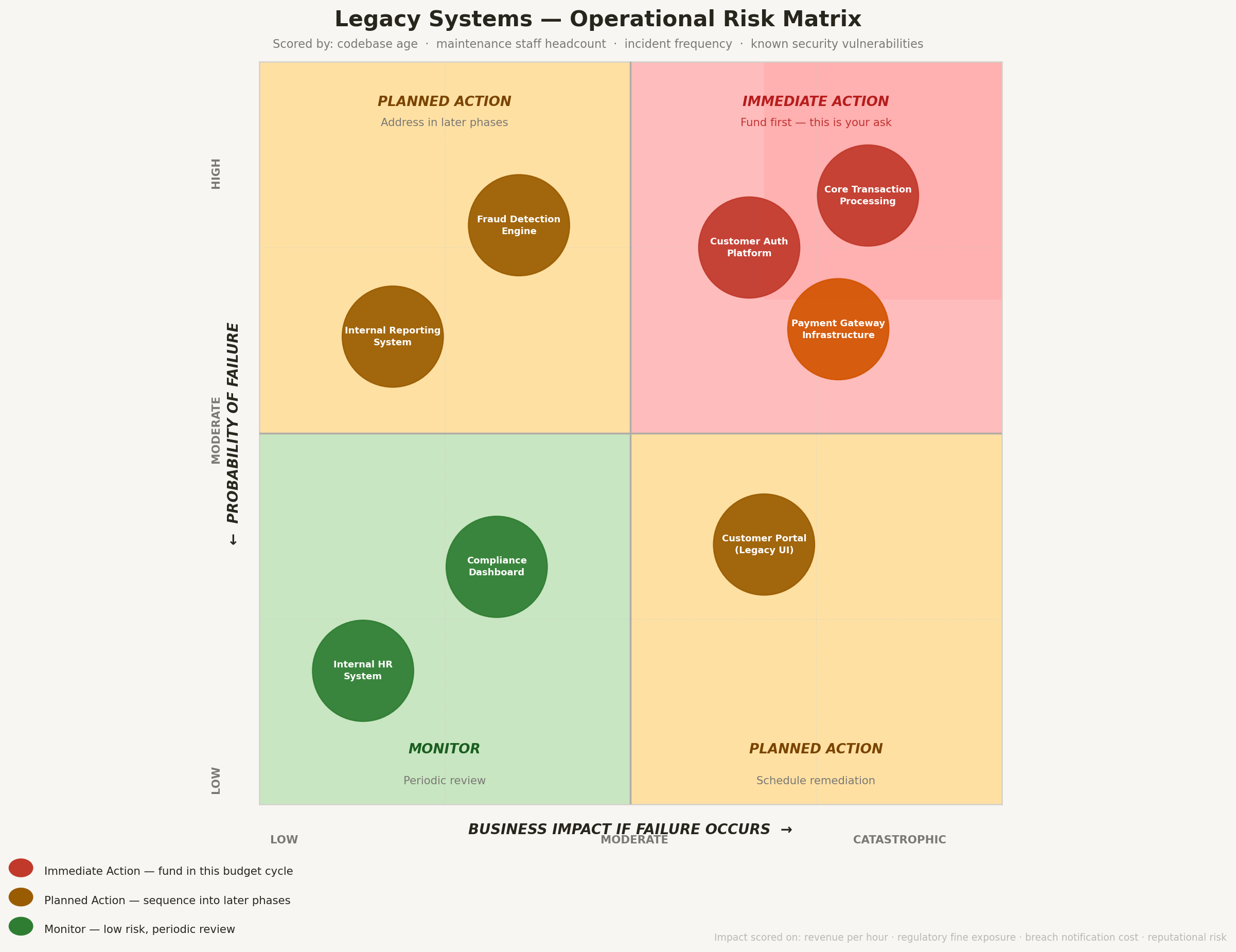
Visual risk matrix guides board action priorities.
Handling Objections
Every board raises the same three objections. Prepare for all of them.
"It still works."
This is the most common and most dangerous objection. According to the CTO Legacy Risk Guide, 50% of organizations delay action because "the system still works." The response: "The system runs, but it cannot be safely changed, it cannot be staffed, and it cannot be insured against failure. A building with a cracked foundation still stands. That does not mean it is safe to occupy."
Back this up with your incident data. How many near-misses in the last 24 months? How long did the last unplanned outage take to resolve? What was the root cause, and has it been fixed? If the answers are uncomfortable, they are exactly what the board needs to hear. For context on the supply-side staffing crisis behind this risk, the workforce data is unambiguous.
"It's too expensive."
This objection assumes that the alternative to spending is saving. It is not. The alternative is spending more, slowly, with no risk reduction. Organizations already consume up to 80% of their IT budgets on legacy maintenance (CTO Legacy Risk Guide). The U.S. federal government's seven unfixed critical legacy systems consume $337 million annually in operational costs (FedScoop).
Frame the investment as a net cost reduction over 3 to 5 years, not an additional expense. Show the board a comparison: current annual maintenance cost plus projected incident cost versus the amortized cost of the resilience investment plus the reduced ongoing maintenance. The numbers almost always favor action.
"We tried before and failed."
This is a legitimate concern. The data confirms it: 74% of legacy modernization projects are initiated but never completed (CTO Legacy Risk Guide). The response is not to dismiss the concern but to explain what will be different. Prior failures typically share common causes: they tried to replace everything at once, they lacked executive sponsorship, or they did not define measurable milestones.
Your proposal addresses all three. Phase 1 targets only the highest-risk systems (the top-right quadrant). The board itself provides governance oversight through quarterly reviews. Every milestone has a measurable outcome. This is not a repeat of past efforts. It is a structured, bounded investment. For a technical overview of what a migration actually entails, including the incremental approach that reduces delivery risk, see our technical guide.
What You Are Asking For
Do not walk into the boardroom asking for "budget to fix old code." That framing guarantees rejection. Instead, frame the ask in three parts:
- Risk reduction. "We are requesting an investment of $X to reduce an annual operational liability currently estimated at $Y. This liability includes projected downtime costs, regulatory fine exposure, rising maintenance spend, and the opportunity cost of engineering capacity locked into legacy maintenance."
- Capacity unlock. "This investment will free Z% of our engineering capacity currently consumed by legacy maintenance, enabling us to deliver [specific product capabilities or integrations] that are currently blocked."
- The insurance premium analogy. Boards understand insurance. You do not buy fire insurance because your building is on fire. You buy it because the cost of the premium is a fraction of the cost of the loss. An operational resilience investment works the same way. The annual investment is a fraction of the exposure it eliminates. If the board would not operate without property insurance, they should not operate without resilience coverage for the systems that generate their revenue.
Be specific. "We are asking for $2.4 million over 18 months to reduce a $12 million annual risk exposure and unlock $3 million in product development capacity" is a fundable proposal. "We need to modernize our systems" is not.
Your board does not need to understand the architecture. They need to understand the exposure. Give them the data, speak their language, and show them a path that is phased, funded, and measurable. The risk of inaction is no longer theoretical. The only question is whether your organization addresses it on its own timeline or on the timeline dictated by the next outage, the next audit, or the next retirement letter.
Related insights
COBOL Developer Retirement Rate vs. Training Pipeline
The average COBOL developer is 58 years old, with approximately 10% of the workforce retiring each year. That rate has only accelerated as the cohort ages and talent is vanishing.
COBOL Job Postings Over Time: Salary Trends and Which Industries Are Still Hiring
COBOL is still a high-value labor market: demand remains strong in banking, insurance, and government, while a shrinking, aging talent pool keeps salaries and especially contract rates elevated.
Mainframe Modernization is a Hard and Fun Problem to Solve
At Hypercubic, we believe the ability to constrain reality for agentic AI will be the defining skill of the next decade of software engineering.
Code Comprehension at Scale: Learning from the Bitter Lesson
Handcrafted tricks break at scale. The future of code comprehension lies in holistic, learning-based systems.